Nick White
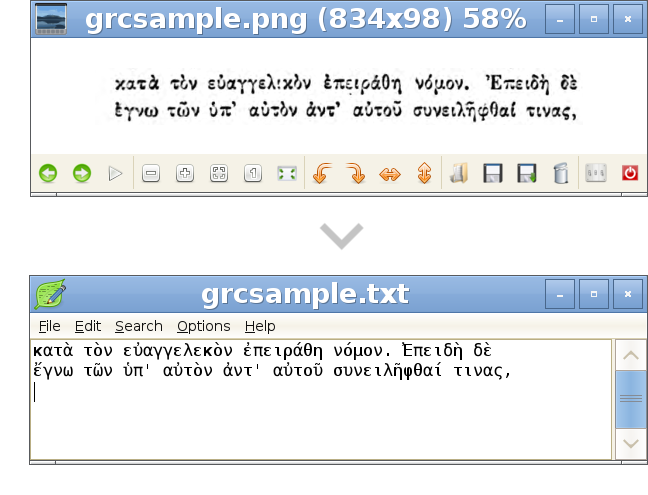
Ancient Greek OCR is free software to accurately convert scans of printed Ancient Greek into unicode text and PDF files, which can be easily searched, copied, archived, and transformed. It uses the excellent Tesseract OCR engine, tailored for Ancient Greek typography, syntax and vocabulary.
It works with Windows, OS X, Linux and Android, and works on personal computers, mobile devices, and large server clusters.
This project was made possible in part by the Institute of Museum and Library Services, LG0611032611; the National Endowment for the Humanities: Exploring the human endeavor; and the Perseus Digital Library Project, as well as the ERC funded Living Poets Project. The Tesseract OCR engine makes this all possible, doing all of the hard work behind the scenes.







 Stumble It!
Stumble It!


No comments:
Post a Comment